截至目前為止,我們已經大概知道如何用資料來建立 machine learning 的模組
以及如何評量它的質量,並且衡量它是否有效
但是光一個模型在真實世界中其實是不夠用的,想像一下
當你做了一個AI的服務,想要服務那些去你網站購買你商品的消費者,這個過程會是怎樣的呢?
這涉及到許多層面,我們稱之為 model deployment
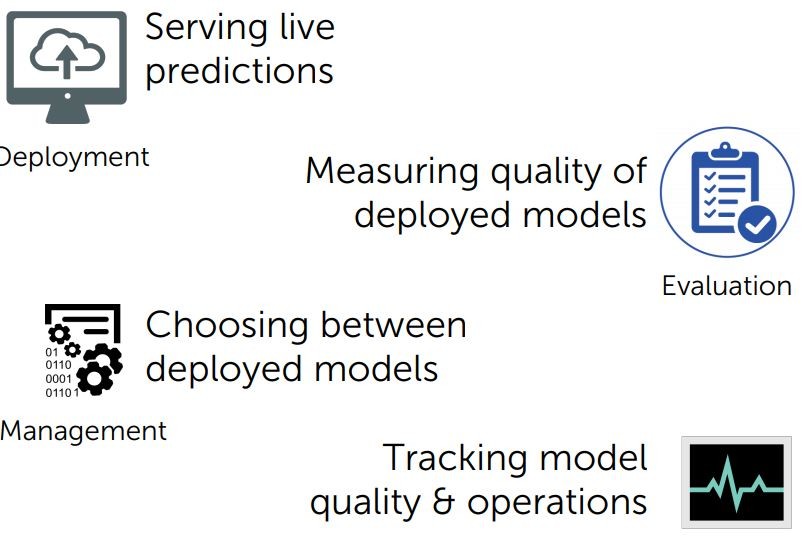
我們把模型來做 Real-time 預測,接著我們會提到如何去衡量模型來保證,它的品質在一個長時間的環境仍然有效用
不只如何還要考慮如何讓模型變得更好,最後對於預測的結果該如何反應
這幾項其實不是分散的,每一項的內容都是彼此關聯
思考一下,你要建立的是一個新的產品推薦系統有百萬級別的消費者評論與喜好,你想讓讓伺服器訓練出模型,並將之運行在購物網站
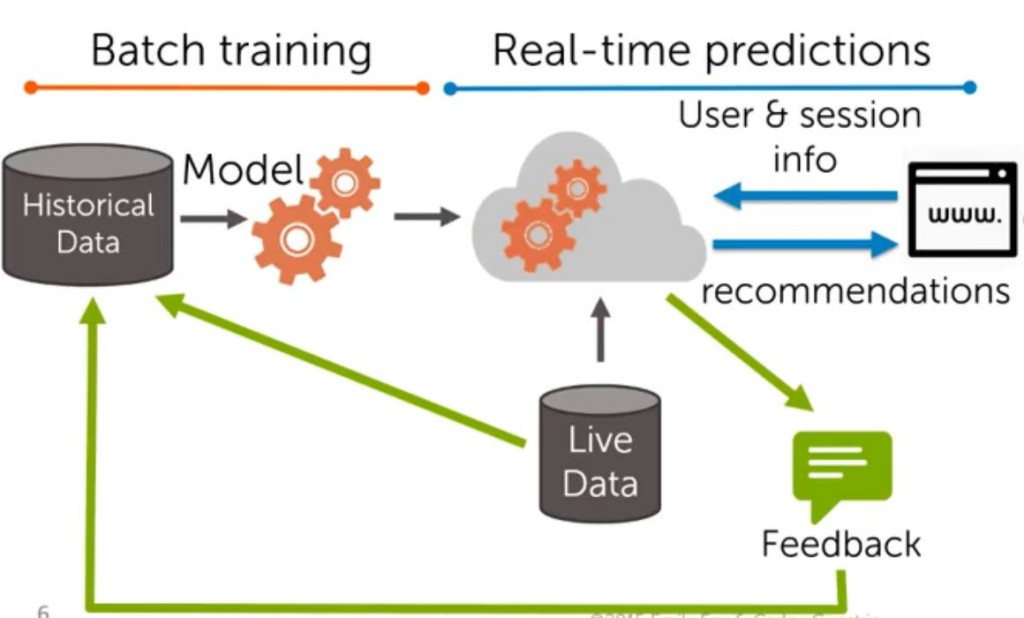
首先你會有一些歷史資料,我們利用這些資料來訓練模式這一部分我們稱為 Batch Training
接著你會把模型運作在伺服器上,你所做的是 serving predictions,這是一個 Real-time system
今天假設有一個網站,網站上會給伺服器有關於消費者的資訊,消費者現在在做什麼?他在觀看那些頁面?它購物車現在暫存了那些商品?
我們的伺服器會透過這些資料來做 Real-time predictions
記得先前那個長頸鹿玩具嗎?其他消費者看到了它,它們可能會買也可能不會買
我可以從系統中得到反饋,其他消費者是否真的夠買了這項商品,這將影響到我們的 Real-time 的 Real-time system
現在我們大概已經有了一點概念,但是關於 Deployment 我們還需要了解更多
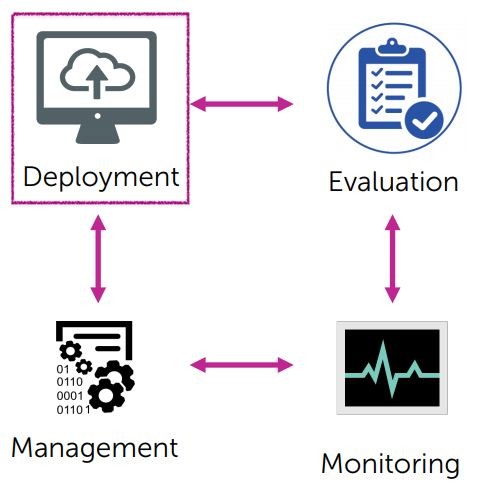
我們接著要來談模型的管理還有評估,以及如何衡量我們監測的資料,剩下的三項其實就是我們學過的模型實際上的應用
先回到 Batch Training 與 Real-time predictions 的流程圖
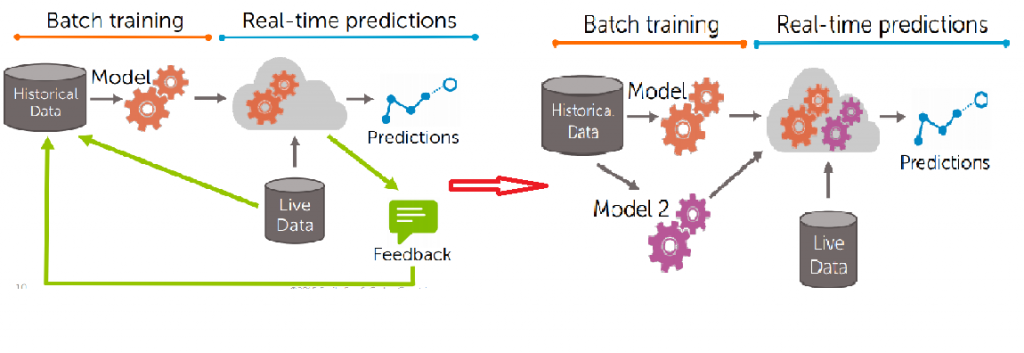
在 Feedback 的部分,消費者是否真的購買了推薦的商品,被 Feedback 到 Historical Data 及 Live Data 當中
而我們利用較新的 Historical Data 來更新模型,假設今天生出了第二個模型(model-2)
我們打算用來改進提供服務的伺服器,並且去探究 model-2 是不是真的比 model-1 來的好
這個問題就是 managing models 中的關鍵問題,中間必須對何時更新?什麼情況下那個用那個模組比較好?來做出取捨
而 monitoring models的關鍵是預測的評估,實際上我們是將預測與度量放在一起了
我們關心的是,向消費者收集那些資料?不僅僅是一開始的 Historical Data 還有 Real-time 正在收集的(消費者獻上一秒購買了什麼?)
以及該採用什麼度量來評價這整套系統?像之前的經典例子,垃圾郵件遮蔽率是90%,這在真實世界中這個系統跟垃圾郵件一樣垃圾
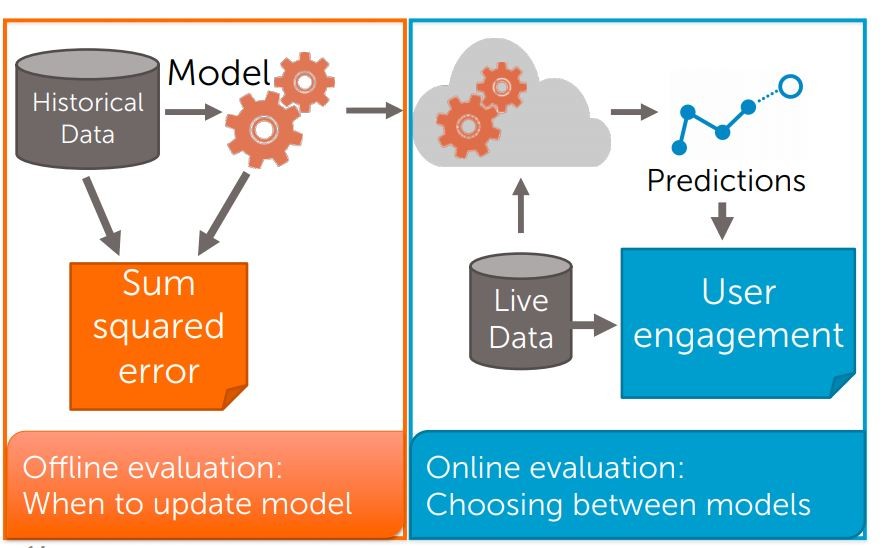
想一想先前評價系統的方式有 minimizing sum squared error,但現在這種方式還正確嗎?
這個模型在 offline 是不錯的評價方式,但在網路商店運作中,你真的關心的只有消費者到底買不買帳
所以 minimizing sum squared error(總和平方差) 只用於 offline 模型的最佳化
至於判斷 model-2 是不是優於 model-1 要怎麼處理呢?這邊的問題是我們是否該改用新的 model-2?
通常這種更新都是伴隨著新的產品、新的消費者(比如穿戴裝置的出現或亞馬遜商店進軍亞洲)
那到底該在 Online 中要如何衡量呢?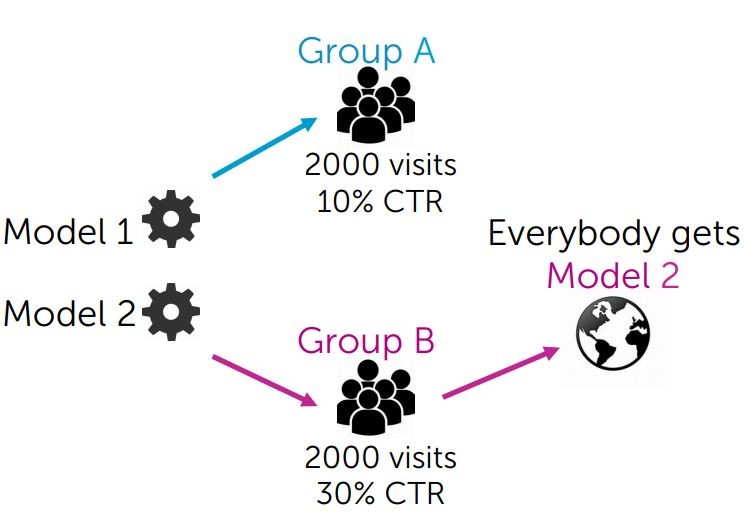
這裡引入一個 A/B Testing 的概念,如同這流程圖一樣直觀,我只要將這兩套模型運行在不同的使用者群裡面(這裡的群集必須夠大,像是美國A與加拿大B)
並且從中收集,到底在一定的時間裡面,那一套模型可以讓最多人結帳



 iThome鐵人賽
iThome鐵人賽